
What is lcp?
lcp is a backend service I wrote that aggregates, processes, and caches data from a number of APIs. This data is then exposed as a REST API. It is written in the Go programming language and runs in a Docker container on my Caprover server. The main goal of lcp is to provide extremely fast and very simplified data fetching for my website. This is mainly thanks to the way that caching is done in a protected memory space and that data is aggregated from multiple sources. Down below is more technical explanations of how lcp works.
System Overview
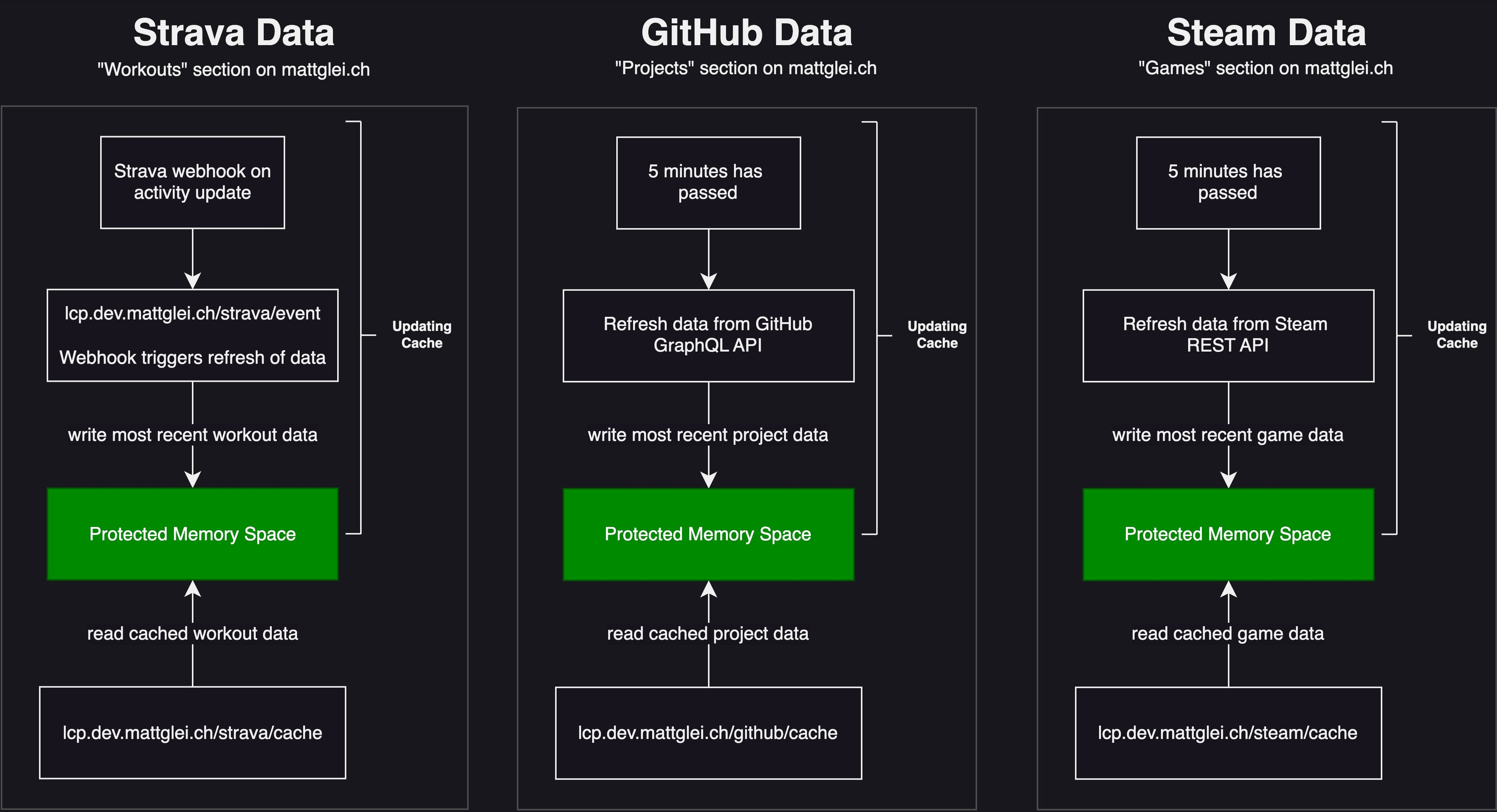
The diagram above illustrates how each cache gets updated. There are two main types of caches here:
- Event-based cache: Cache is updated based on an event like receiving a webhook. This is ideal as it provides real-time cache updates. An example of this is the Strava cache which receives webhook events for new activities.
- Time-based cache: Cache is updated based on a given time interval. An example of this is the Steam cache which refreshes every 5 minutes.
A protected memory space in this context is just a mutex lock. All of this caching happens in different threads so to ensure thread-safe memory interactions this protected memory space is used.
Main Benefits
When the site makes a request to load data from lcp.dev.mattglei.ch/strava/cache all it is doing is reading the cached data from memory. No expensive database queries or anything.
Data can be processed and aggregatedWith Steam, for example, there is no endpoint from the Steam REST API to get your games with the achievement data all in one request. So, for every game you need to make a request to load the achievement data. All of this is done by lcp so that when a request is made to lcp.dev.mattglei.ch/steam/cache it returns the games with their achievements all in one request. This cuts down +25 requests to the Steam REST API with each request taking +400ms down to one request that takes ~200ms.
Prevent hitting API rate limitsMost major APIs have rate limits. The Strava API for example only allows 100 requests every 15 minutes. If I wasn't caching this data and was simply requesting the data every time that someone visited the site I could very easily encounter rate limiting. The REST API that is exposed by lcp has no rate limits, so my site can hit it every time a request is made without having to worry about rate limits.
Prevent downtimeSometimes APIs have problems and are down. Because lcp caches the data and is essentially saving a copy, it does't have to depend about the source data being up. Downtime is more often than people realize and when you're using multiple APIs, the chance of one of them being down is even greater.
Design Decisions
There are simpler solutions to purely load data onto my website. Why did I build this then? Here are a few reasons why:
- Data caching and fetching are independent of the framework I am using to build my website. This separation of responsibilities is important as every so often I like to rebuild my personal website and try out a new framework (hence this being the 4th version of my personal website). My last personal website was built in Svelte Kit for example.
- I want to use this data in other projects. For example, I use lcp in the ssh version of this website. To have a central place to access all of this data instead of everything just getting pulled from my site is a better architecture in my opinion.
- It has been a little while since I worked in Go and wanted to do a new project in the language.
Go is a popular language for building REST APIs. I've been using the language for a few years now and have a few reasons why I selected it for V2 of lcp:
- The standard library makes it very easy to work with. I don't have to import a bunch of different packages for working with things like JSON and requests. A lot of these features come straight out of the box with the fantastic standard library.
- Go is very fast. Although I am not handling massive amounts of web traffic, being able to handle a request on the microsecond scale (literally) is great. Very happy with the performance I am getting.
- I have a lot of experience writing Go code and am very comfortable in the language.
V1 of lcp was written in the Rust programming language. There are a few reasons why I wanted to rewrite lcp and create a second version:
- I wanted to make a more generic cache. In V1 of lcp a lot of the codebase was a cache specific. This added a lot of code for each cache with zero benefits. Making a generic cache greatly reduced the amount of code/complexity of lcp V2.
- Go is easier to make APIs with compared to Rust in my opinion. Rust is pretty easy using the rocket.rs framework, but working with the Go standard library makes things easier.
- V1 of lcp used AWS S3 which I ended up replacing with a Minio instance running on my Caprover server. The current Minio library for Rust is not stable, but the one for Go is. Switching to Go allows me to use the stable Minio library and cut out using S3. I replaced S3 with Minio because I didn't want to pay any costs associated with storing images from mapbox (see below for more details).
Using webhooks is ideal as it only reaches out to API when the data has actually changed. Not all APIs or data changes support webhooks which is why polling has to be used instead. For the GitHub API, there is no webhook for when the user's pinned repositories are changed (which is what the data is based on). For the Steam API, they simply don't support webhooks so polling is the only option.
Why have three separate endpoints instead of bundling them all together in one?First of all, having each cache be independent of each other provides a separation of concerns which makes the application easier to maintain/work with. It also allows each section to load independently on the front end. Using features from Next.js like streaming and even experimental features like partial pre-rendering (PPR) allows for each section to quickly be loaded in asynchronously.
Strava Maps
One interesting technical problem that I faced in this project was loading Mapbox images from their API onto the site. These images are the maps of my recent workouts and are statically generated based on geojson data from Strava. Unfortunately, Mapbox static images don't work with the Next.js Image component, a React component for greatly optimizing images for the web. This is mainly due to the way in which Mapbox tokens are secured and how Next.js optimizes images on the server. I took this problem as an opportunity to learn AWS's S3 object storage so that lcp could just request these images and send them to S3. Once they are on S3 Next.js can load the images properly and still utilize all of its optimization features. This is yet another expensive operation that can be done by lcp when a cache is updating.